Data resource profile: the allergic disease database of the Korean National Health Insurance Service
Article information

Abstract
Researchers have been interested in probing how the environmental factors associated with allergic diseases affect the use of medical services. Considering this demand, we have constructed a database, named the Allergic Disease Database, based on the National Health Insurance Database (NHID). The NHID contains information on demographic and medical service utilization for approximately 99% of the Korean population. This study targeted 3 major allergic diseases, including allergic rhinitis, atopic dermatitis, and asthma. For the target diseases, our database provides daily medical service information, including the number of daily visits from 2013 and 2017, categorized by patients’ characteristics such as address, sex, age, and duration of residence. We provide additional information, including yearly population, a number of patients, and averaged geocoding coordinates by eup, myeon, and dong district code (the smallest-scale administrative units in Korea). This information enables researchers to analyze how daily changes in the environmental factors of allergic diseases (e.g., particulate matter, sulfur dioxide, and ozone) in certain regions would influence patients’ behavioral patterns of medical service utilization. Moreover, researchers can analyze long-term trends in allergic diseases and the health effects caused by environmental factors such as daily climate and pollution data. The advantages of this database are easy access to data, additional levels of geographic detail, time-efficient data-refining and processing, and a de-identification process that minimizes the exposure of identifiable personal information. All datasets included in the Allergic Disease Database can be downloaded by accessing the National Health Insurance Service data sharing webpage (https://nhiss.nhis.or.kr).
INTRODUCTION
Amid increasing global efforts to understand the effects of environmental factors associated with allergic diseases (e.g., environmental pollution, climate change, and harmful substances) on human disease and health, Korea is also seeking to develop effective policies to manage allergic diseases. The increasingly severe problems posed by air pollution, such as fine particulate matter (PM) and yellow dust, have prompted numerous researchers to study the effects of these pollutants on morbidity and mortality. Studies have reported that air pollution and other environmental factors not only increase the prevalence of cancer and cardio-cerebrovascular diseases, but also have impacts on premature deaths and the use of medical services [1-3].
Traditionally, health was defined as a disease-free state, and the medical community focused on treating diseases from a biological perspective. Since the 1970s, the increasing frequency of chronic and lifestyle-related diseases led researchers to acknowledge the power of lifestyle factors as a determinant of health, spurring efforts to prevent diseases based on an improved understanding of the various factors that determine health [4]. Since the late 1980s, an increasing emphasis has been placed on the importance of healthcare policies for managing physical factors at the society-wide and environmental levels, reflecting the awareness that individual efforts are not sufficient to prevent disease and to maintain health [5]. In recent years, disease outbreaks and health equality problems caused by various factors in the physical environment (e.g., climate change and environmental pollution) have become important social issues, along with the social environment. These developments have sparked interest in related research. For instance, the World Health Organization has reported that one-fourth of deaths are caused by preventable environmental factors of allergic diseases, with air pollution (e.g., PM, sulfur dioxide [SO2], and ozone [O3]) having an especially large effect.
Generally, it has been easy to acquire data in Korea for research purposes through the National Health Insurance Database (NHID), which contains records from the only medical insurance program in the country (provided as a form of social insurance) [6]; however, demand has emerged for additional datasets to use for research into environmental factors of allergic diseases. Multiple studies have investigated these issues, although researchers have specifically pointed out the need for a reliable database that would not require repeated processing and would be suitably constructed for aligning data sets relevant to environmental factors. Researchers have been especially interested in probing how environmental factors affect the use of medical services, as well as the prevalence of death and diseases, and the most common way to analyze big data has been to explore how daily changes in environmental factors in certain regions influence patterns of medical service utilization [7-10]. Considering this demand, we have constructed a database, which we have named the Allergic Disease Database, containing values broken down on the level of district and day to reliably align the National Health Insurance Service (NHIS) big data with data on other environmental factors of allergic diseases.
DATABASE DESCRIPTION
Database design
The Allergic Disease Database was established using the NHID, which is an open resource of personally unidentifiable data specifically processed for research purposes. The database contains information on daily medical service utilization, yearly population and number of patients, address codes, and averaged geocoding coordinates by district (Table 1). The daily medical service utilization data comprise a statistical table of daily outpatient visits, inpatient visits, and emergency medical visits by patients’ residential district and basic characteristics (sex, age, and duration of residence). The data on the yearly population and number of patients consist of the number of residents (as of December each year) and the number of patients by disease, residential district, and patients’ basic characteristics (sex, age, and duration of residence). The address and average geocoding coordinates data include address codes from the Ministry of the Interior and Safety, the effective date of address codes, as well as the averaged geocoding coordinates (X, Y) by district. Daily medical service utilization data were calculated based on the serial number of addresses, while the data on the number of population and patients, as well as the address and resident average coordinates, were compiled based on address codes from the Ministry of the Interior and Safety, and should be analyzed with a primary key to understand the relationship between address codes and address serial numbers.

Components of the Allergic Disease Dataset
Baseline population
The NHID has gathered information from 2002 to the present, and includes socio-demographic information and medical service use data from all Korean residents. The current version of the database is built on 5-year data from 2013 to 2017, and information from 2002 onwards will be added to the database on an ongoing basis. We considered people who had health insurance during this period, accounting for 99% of all Koreans. The collected data sets mainly include NHIS subscriber information and diagnosis and treatment history. Korea has adopted a single-provider health insurance system administered by the NHIS, in which all medical service providers and residents are mandated to participate. The single insurer (NHIS) collects individuals’ basic socio-demographic characteristics such as sex, age, residential address, birth, death, and disability status, as well as insurance type and premium data. All medical service providers in Korea file claims for reimbursements through the NHIS, which allows the insurance provider to collect patients’ personal information and data on the provider, service start date, diagnosis code, cost of service, and type of care.
Structure and composition of the database
In order to build the Allergic Disease Database, we first extracted individual IDs, the number of claims, service start date, and diagnosis code variables from the claims database of the NHID. The variables of residence area, sex, age group, and residence period were extracted from the eligibility database of the NHID. We then integrated information based on the individual ID and grouped the integrated information based on the serve start date, address serial number, sex, age group, duration of residence. Next, statistical values for medical use (e.g., outpatient/inpatient visits, and emergency medical visits) were calculated. Finally, the daily medical service utilization data consist of 15 tables, divided into asthma, atopic dermatitis, and allergic rhinitis disease groups by year from 2013 to 2017. Each table has about 130 million rows and consists of 8 columns, including the total number of populations by region and socio-demographic characteristics, as well as address codes. The yearly population and number of patients consists of 5 tables for each year from 2013 to 2017. Each table has about 100,000 rows and consists of 10 columns, including information on medical utilization by patients’ characteristics based on the date and the region. Lastly, the address information and averaged geocoding coordinates by district are presented in 1 table, with a total of 3,679 rows. The layout is provided in Supplementary Material 1.
Suggested outcome variables and their distribution
Variables at the personal level
There are many ways to define allergic disease groups and subjects in the NHID. This study selected the asthma, atopic dermatitis, and allergic rhinitis disease groups as major allergic diseases, in accordance with the “General guidelines for classification of disease codes and procedure codes for statistical analyses” published by the NHIS [11]. The number of patients varied considerably depending on how many subdiagnoses were included. In 2017, the medical utilization rate of each disease group relative to the total population when including the main diagnosis only, the main and secondary diagnoses, and the main diagnosis and all subdiagnoses were 2.9%, 5.7%, and 11.4%, respectively, for asthma; 1.8%, 2.9%, and 4.7%, respectively, for atopic dermatitis; and 13.1%, 36.9%, and 51.3%, respectively, for allergic rhinitis (Supplementary Material 2). This database was constructed using both the main diagnosis and all subdiagnoses to cover as many patients as possible related to the disease. This is because the classification of high-dimensional statistical data is usually not amenable to standard pattern recognition techniques because of an underlying small sample size problem [12]. The target medical services were diagnosis codes for asthma (J45, J46), atopic dermatitis (L20), and allergic rhinitis (J30) at all medical institutions (medical, public health organizations, and psychiatrists), except visits to oriental medicine providers and dentists, visits with an excluded diagnosis, and visit with missing address information.
Repeated variables
Instances of medical service utilization included daily outpatient, inpatient, and emergency visits. The number of inpatient visits was calculated using the concept of “episodes,” according to which readmission within 1 day of discharge was considered as the same visit, as this concept is often used to adjust for installment bills in cases of long-term hospitalization. The number of visits during hospitalization was counted in 2 ways: counting the admission date only, and counting every day as a visit over the entire period. Emergency visits were counted as cases billed under the emergency care management fee (Insurance number code: AC101-AC105, V1100-V1400). The trends in the sum of monthly outpatient visits and the sum of inpatient visits based on the date of admission between 2013 and 2017 can be found in Figure 1. The total number of patients in the population by year and in 2017 by sex, age, duration of residence, and day of the week is presented in Table 2.
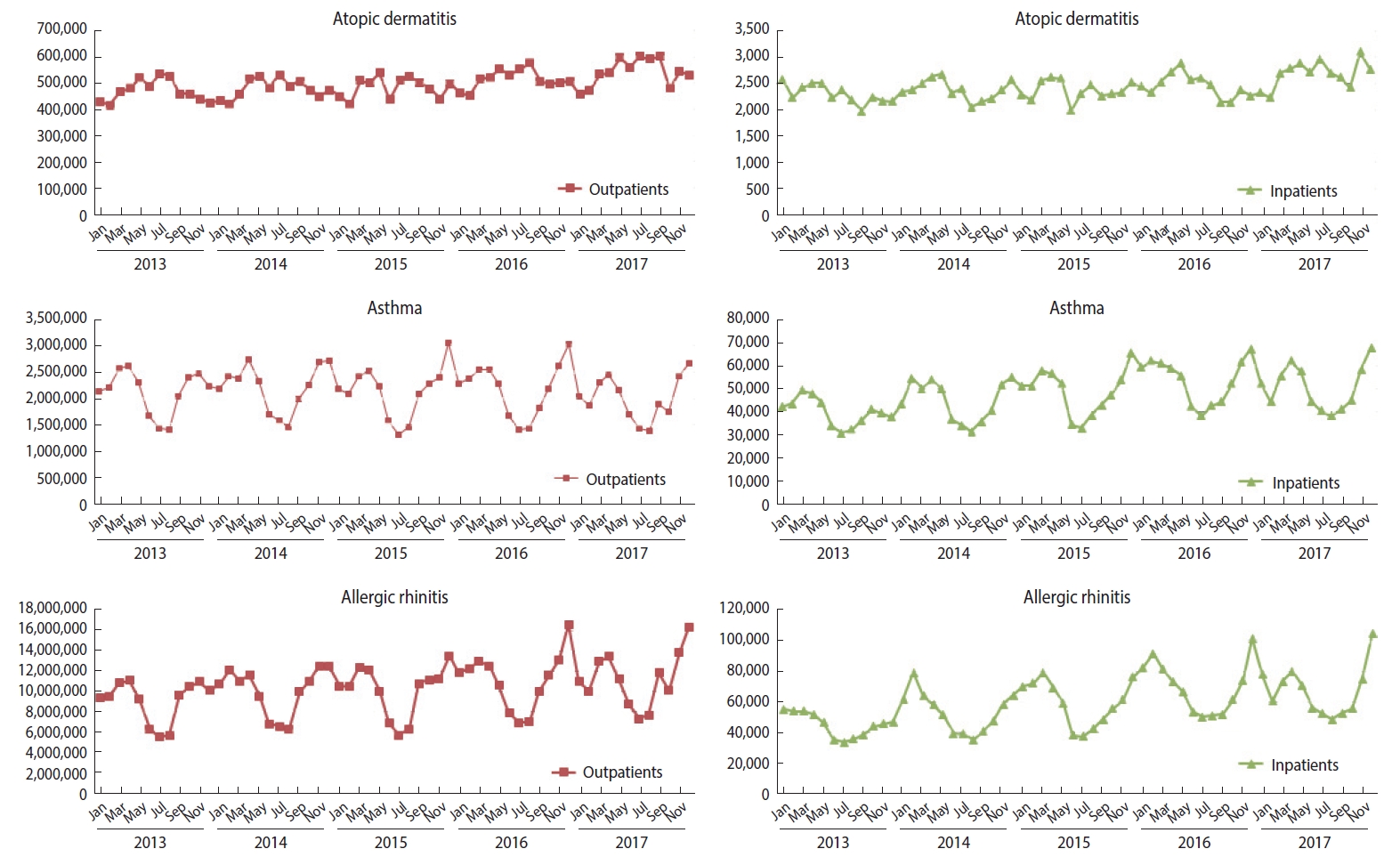
The trends in the sum of monthly outpatient visits and the sum of inpatient visits based on the date of admission between 2013 and 2017.
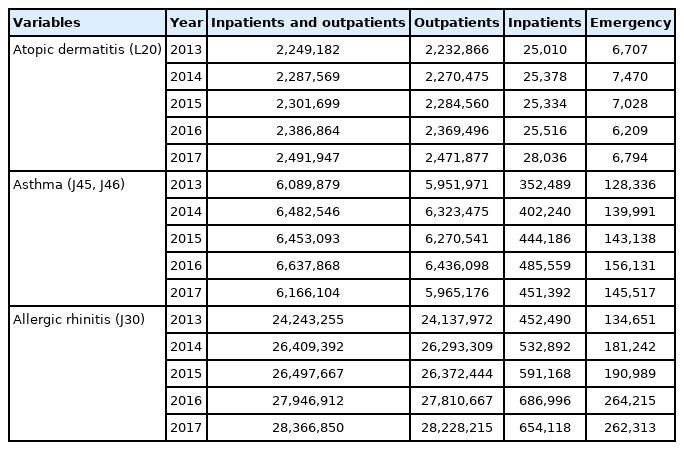
Total number of patients in the yearly population and in the patient dataset
Population-level variables
The yearly population and the number of patients were counted based on individuals with eligibility data as of December in each year, excluding those without detailed address data. The number of patients was counted for inpatient, outpatient, and emergency visits by district (eup, myeon, and dong; the smallest-scale administrative units in Korea) and socio-demographic characteristics (sex and age), removing overlapping patients who had the same main diagnosis code. The daily number of visits for hospital service utilization is listed in Table 3.
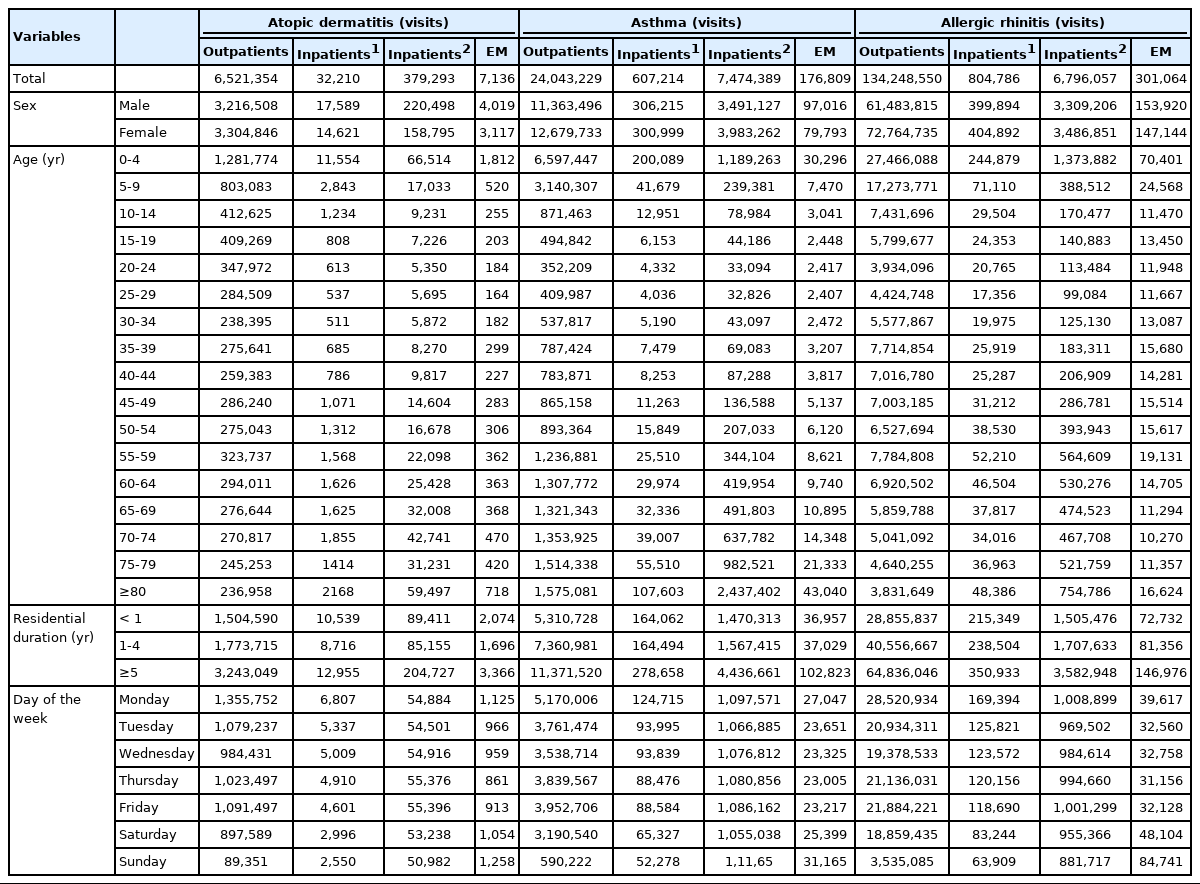
Total number of visits in the daily medical service utilization dataset (2017)
Suggested explanatory variables
Multi-level variables
Addresses and averaged geocoding coordinates
In the address and averaged geocoding coordinate dataset, new serial numbers for addresses were assigned after integrating the effective date of address codes, cases where the address code changed within a single district, and districts with very small populations that would make personal data identifiable. This dataset can be used as a mapping table to identify the address serial numbers for medical service utilization data. The averaged geocoding coordinate value data can be used to calculate distance values when aligned with data from different institutions.
The address code serial numbers were set by assigning the same number for each integrated district. The requirements for integration were as follows: districts that went through any changes (creation, deletion, division, integration) at least once between 2013 and 2017 were integrated under the same number, using the “Resident registration address code change history” at the Ministry of the Interior and Security webpage (http://www.mois.go.kr). Districts with an extremely small number of residents were integrated with nearby administrative units and were assigned the same serial number to prevent the identification of personal data. Districts that had fewer than 5 individuals in any category at any point between 2013 and 2017 by district, sex, and age were selected as eligible for de-identification and were assigned a serial number after integration with nearby administrative units. A total of 351 district-level units were integrated (Supplementary Material 3).
Variables at the personal level
The daily medical service utilization dataset contains the number of daily visits between 2013 and 2017 broken down by patients’ characteristics (address, sex, age, and duration of residence), including figures for each day of the week. The characteristics of patients were determined by referencing the information recorded in the eligibility data for the month of medical service use (e.g., December 2012 eligibility data were referenced when a patient used a service in December 2012), sex was defined as male and female, and age was grouped in 5-year intervals. Duration of residence was defined as the duration of residence in a certain region over the past 10 years based on the address data for the applicable months. For example, if a patient lived for 9 years and 8 months in address code A and for 4 months in address code B, the utilization of medical services in address code A would fall into category 3 (5 years or longer), while the utilization of medical services in address code B would fall in category 1 (1 year or less).
RESEARCH APPLICATION
Prior data resource use
Previous studies on allergic diseases using NHIS claim data have mainly used generalized additive models that refined the claims data into data on the daily number of visits for outpatient, inpatient, and emergency visits, which were aligned with air pollution data from the Urban Air Monitoring Network [7,9]. Factors influencing health and air pollution data (PM with aerodynamic diameter up to 10 μm, O3, nitrogen dioxide [NO2], SO2, and carbon monoxide) were most commonly used as analysis variables, while factors such as day of the week, climate variables, and long-term trends were controlled for using locally weighted regression smoothing functions. However, the results varied depending on target selection (e.g., when analyses were limited to children, the elderly, certain regions or diagnosis codes, or diagnosis and pharmaceutical codes), and analyses of inpatient cases showed variation according to the criteria used to calculate the number of inpatient episodes and the selection of lag effect dates.
In previous studies on factors affecting atopic dermatitis, Lee et al. [9] found no statistically significant variables, while Kim et al. [8] demonstrated that O3 affected the number of outpatient visits and fine PM significantly affected the number of outpatient visits only in some regions. For asthma, Lee et al. [9] concluded that fine PM, O3, and NO2 affected the number of patients while Kim et al. [8] reported that O3 meaningfully affected outpatient visits and that O3 and fine PM meaningfully influenced the number of inpatients in some regions. Many studies have concluded that fine PM levels affected asthma [9], although Kim et al. [8] concluded that O3 meaningfully affected the number of outpatients in all metropolitan areas across the country, whereas fine PM only affected the number of outpatients and inpatients in some regions.
Further application
The proposed Allergic Disease Database can be used to predict future allergic disease occurrence and regional medical use through time series analysis [13,14]. It can be used to support the design of effective public health policies to prevent allergic diseases and health promotion. It will also be possible to conduct specific forms of longitudinal studies with sample cohorts, performing cross-sections at intervals over time based on socio-demographic and allergic disease information contained in the database [15,16]. In addition, the database can be used to conduct further analyses by combining various external data. By adding environmental parameters (e.g., PM, yellow dust, and SO2) to the database, it will be possible to analyze the transient effects of those parameters on allergic disease risk by conducting case-crossover studies [17-19].
STRENGTHS AND WEAKNESSES
The Allergic Disease Database has the following strengths: First, its data can be easily accessed by simply logging onto the webpage, without having to apply for access to the data. Second, it is possible to break down the results by small-scale address units. The Allergic Disease Database provides addresses down to the district level (eup, myeon, and dong), while other data sets shared or provided upon researchers’ request normally provide addresses only at the city, province, and county level. Third, the database saves time for data refining and processing. The accuracy of the address codes has been improved by refining the data with effective address codes in the applicable year, and the adjusted and claimed data were transformed into daily data by accounting for address code changes. Outpatient visit data were refined by episodes to reduce the work needed for data refinement and to utilize the data efficiently. Fourth, the database provides results for different types of medical service utilization, including outpatient, inpatient (by admission start date and duration of admission), and emergency care. Fifth, there is a reduced risk of personal identification through de-identification. Although the database was not subject to de-identification guidelines due to its form as a statistical data, the risk of identification was minimized by grouping together districts with fewer than 5 residents in any category. Lastly, it is possible to explain the characteristics of allergic disease factors over time by analyzing the pattern of seasonal fluctuations in the distribution of disease prevalence. We plan to support more diverse analyses by expanding the target diseases to include cardiovascular diseases and infectious diseases affected by the environment.
The acknowledged limitations of this database are as follows: First, it is difficult for researchers to perform a customized analysis because the information provided in the database is in the form of statistical values calculated based on a predefined operational definition. In addition, since the allergic diseases currently under consideration are chronic, there is a limitation in evaluating the incidence rate only by analyzing utilization of medical services. In order to solve this problem, operational definitions should be subdivided according to the characteristics of the disease. Therefore, it is necessary to define and update operational definitions in consideration of drugs and treatments for specific diseases in consultation with academic researchers and experts in the future. Second, the risk of type I error (false positive) is considerable, because the main diagnosis and all subdiagnoses were considered when extracting the disease group. Type I error refers to a situation in which the test result erroneously indicates the presence of the disease, whereas type II error (false negative) refers to the opposite situation in which the test result does not indicate the presence of the disease. If we only use the main diagnosis, excluding all subdiagnoses, type 1 error decreases but type 2 error increases. In this study, we used all subdiagnoses as it was considered important to reduce type 2 error. However, depending on the researcher’s study design, reducing type 1 error may be more important. Therefore, we plan to conduct further analyses on various subdiagnoses. Third, autocorrelation problems may occur in repeated analyses by region or episode. If researchers do not consider a proper normalization process or multi-level analysis, non-significant results can be distorted into significant results. Fourth, the actual number of individuals affected by these illnesses may be different from the values provided in this database, as the values in this database were calculated based on diagnoses. Fifth, it may not be possible to analyze integrated districts individually.
DATA ACCESSIBILITY
All datasets included in the Allergic Disease Database can be downloaded by accessing the NHIS data sharing webpage (https://nhiss.nhis.or.kr). Sign up, sign in, and click “Data application” → “Allergic disease DB.” The Allergic Disease Database manual and sample data can be downloaded by clicking “Download the manual and sample data,” and the entire dataset can be downloaded by clicking “Application for data use” after submitting the name of the research director and purpose of research and clicking “Apply.”
All data files are provided in CSV format. There are a total of 15 files, including medical use data by year (5 files) and by disease (3 files), yearly population and number of visits (5 files), and data on address codes and averaged geocoding coordinates (1 file). A detailed user manual can be downloaded at the same time, and any questions can be directed to the NHIS Big Data Office at +82-33-736-2462.
Ethics statement
The Ethics Committee of the NHIS waived the need to obtain consent for the collection, analysis, and publication of the retrospectively obtained and anonymized data for this non-interventional study.
Supplementary Materials
Supplementary materials are available at http://www.e-epih.org/.
Notes
CONFLICT OF INTEREST
The authors have no conflicts of interest to declare for this study.
FUNDING
This study was supported by a research grant of the NHIS.
AUTHOR CONTRIBUTIONS
Conceptualization: JHP, YYK, EJL. Data curation: EJL, JHP, YYK, KDC. Formal analysis: YEK, MJG, JIS. Funding acquisition: JHP. Methodology: SY, DWK, YEK. Project administration: EJL, MJG, JIS. Visualization: MJG, JIS.Writing – original draft: SY, EJL, YYK, JHP, KDC, MJG, JIS. Writing – review & editing: SY, DWK, YEK.
Acknowledgements
None.