Articles
- Page Path
- HOME > Epidemiol Health > Volume 39; 2017 > Article
-
Original Article
Exploring neighborhood inequality in female breast cancer incidence in Tehran using Bayesian spatial models and a spatial scan statistic -
Erfan Ayubi1
 , Mohammad Ali Mansournia1, Ali Ghanbari Motlagh2, Alireza Mosavi-Jarrahi3, Ali Hosseini4, Kamran Yazdani1
, Mohammad Ali Mansournia1, Ali Ghanbari Motlagh2, Alireza Mosavi-Jarrahi3, Ali Hosseini4, Kamran Yazdani1 -
Epidemiol Health 2017;39:e2017021.
DOI: https://doi.org/10.4178/epih.e2017021
Published online: May 17, 2017
1Department of Epidemiology and Biostatistics, School of Public Health, Tehran University of Medical Sciences, Tehran, Iran
2Department of Radiotherapy, Shahid Beheshti University of Medical Sciences, Tehran, Iran
3Department of Health and Community Medicine, Shahid Beheshti University of Medical Sciences, Tehran, Iran
4Department of Geography and Urban Planning, University of Tehran, Tehran, Iran
- Correspondence: Kamran Yazadni Department of Epidemiology and Biostatistics, School of Public Health, Tehran University of Medical Sciences, 16 Azar Ave., Tehran 644614155, Iran E-mail: kyazdani@tums.ac.ir
• Received: March 13, 2017 • Accepted: May 17, 2017
©2017, Korean Society of Epidemiology
This is an open-access article distributed under the terms of the Creative Commons Attribution License (http://creativecommons.org/licenses/by/4.0/), which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
Abstract
-
OBJECTIVES
- The aim of this study was to explore the spatial pattern of female breast cancer (BC) incidence at the neighborhood level in Tehran, Iran.
-
METHODS
- The present study included all registered incident cases of female BC from March 2008 to March 2011. The raw standardized incidence ratio (SIR) of BC for each neighborhood was estimated by comparing observed cases relative to expected cases. The estimated raw SIRs were smoothed by a Besag, York, and Mollie spatial model and the spatial empirical Bayesian method. The purely spatial scan statistic was used to identify spatial clusters.
-
RESULTS
- There were 4,175 incident BC cases in the study area from 2008 to 2011, of which 3,080 were successfully geocoded to the neighborhood level. Higher than expected rates of BC were found in neighborhoods located in northern and central Tehran, whereas lower rates appeared in southern areas. The most likely cluster of higher than expected BC incidence involved neighborhoods in districts 3 and 6, with an observed-to-expected ratio of 3.92 (p<0.001), whereas the most likely cluster of lower than expected rates involved neighborhoods in districts 17, 18, and 19, with an observed-to-expected ratio of 0.05 (p<0.001).
-
CONCLUSIONS
- Neighborhood-level inequality in the incidence of BC exists in Tehran. These findings can serve as a basis for resource allocation and preventive strategies in at-risk areas.
- Statistics have shown that the incidence rate of breast cancer (BC) is 24 per 100,000 in women in Iran [1]. The annual number of new BC cases is projected to increase from 5,000 in 2000 to 15,000 in 2030 [2]. BC has a poor prognosis in Iran; it is the third leading cause of death from cancers, accounting for 16% of cancer deaths [3]. Most BC patients are diagnosed at advanced stages in Iran [3].
- The incidence and mortality of BC have been attributed to many individual-level risk factors [4-9]. Regardless of these risk factors, it has been found that the incidence and mortality of BC are associated with place-based and area-based risk factors [9,10]. While many studies in other countries have considered the spatial patterns of BC at the census tract or zip code level [9,11,12], spatial patterns in the incidence of BC have been studied only at the provincial level in Iran [13-15]. For example, the overall incidence of BC in the population living in Tehran province was 31.5 per 100,000, which is greater than the rates observed in other provinces [16]. Therefore, studies should focus on identifying spatial patterns of BC incidence on finer geographic scales to understand health needs and to optimize health care allocation [9-11].
- When studying the spatial patterns of disease on a finer geographic scale, however, some challenges must be considered. Estimated rates and observed associations can involve a degree of bias due to spatial autocorrelation, population size heterogeneity, and small-area effects [17]. Two methods, empirical spatial Bayesian smoothing and the Besag, York, and Mollie (BYM) spatial model, have been used to offset these challenges by considering spatial autocorrelation and spatial heterogeneity among geographic units [11,18,19].
- With these issues in mind, our objectives in this study were (1) to estimate the smoothed standardized incidence ratio (SIR) among neighborhoods in Tehran, and (2) to identify clusters of higher or lower than expected incidence of female BC in Tehran.
INTRODUCTION
- Study area
- A retrospective study design was used in Tehran, the capital of Iran. This city has 22 districts. The geographical units of the study were 374 neighborhoods in the city of Tehran.
- Data sources
- Information about incident cases of female BC in Tehran from March 2008 to March 2011 was obtained from the cancer registry of the Ministry of Health of Iran. Patients’ street of residence was geocoded to the neighborhood. The population of women aged 15 and over in each neighborhood was obtained from the national census of 2006 and 2011.
- Statistical analysis
- The number of the observed events in each neighborhood follows a Poisson distribution,
- where Oi, Ei, and θi are the observed number, of casesnumber, the expected number of cases, and the relative risk for neighborhood i, respectively. The number of expected events is calculated as follows:
- where ni is the number of women aged 15 and over in neighborhood i
- Besag, York, and Mollie model
- Overdispersion or extra-Poisson variability is a challenge when the Poisson model is applied for the count data in a spatial analysis. Overdispersion occurs in the presence of spatial autocorrelation in the residual values. The concept of spatial autocorrelation refers to the idea that due to spatial components, the local estimates of disease risk for neighboring areas are assumed to be correlated. The effect of overdispersion due to spatial autocorrelation on the results is strong if the small-area problem is present [18].
- To offset these challenges, hierarchical models such the BYM model have been introduced [18]. In the BYM model, unmeasured spatial factors are controlled for using suitable random effects, as shown in equation:
- where α is a the log-relative risk baseline, and vi and ui indicates random random-effects components regarding to spatial and non-spatial factors.
- Spatial autocorrelation across neighborhoods (vi) is induced by the conditional autoregressive (CAR) model. The CAR model represents risk factors with spatial structures, so that specific risk estimates of a given area will tend to shrunk shrink toward a local mean. The CAR model within the BYM model is as follows:
- where
- If areas i and j are neighbors of each other, the weight is equal to 1, and otherwise the weight is 0.
- The random effect of ui represents risk factors with non-spatially structures, so such that that the specific risk estimate of a given area will tend to shrunk shrink toward a the global mean of the study area. This component in the BYM model is as follows:
- The parameters
- We implemented a Markov-chain Monte Carlo (MCMC) simulation for estimating all parameters in the BYM model. The Gibbs sampler as a specific MCMC was used to produce random samples through the parameter space. The convergence of the model was evaluated by Brooks-Gelman-Rubin statistics [18]. This statistic method evaluates MCMC convergence by comparing the within-chain variance to the between-chain variance, with values close to 1 indicating the degree of convergence [18]. We ran the MCMC model with 100,000 iterations, ignoring the first 5,000 iterations as burn-in. Iterations started from overdispersed initial values on 2 parallel chains. OpenBUGS version 3.2.3 (http://www.openbugs.net/w/Downloads) was used to implement the BYM model.
- Spatial empirical Bayesian methods
- Another available method for correcting bias in raw estimates of the SIR is spatial empirical Bayesian (SEB) methodsanalysis. The SEB method causes the rates in neighborhoods in areas without clear spatial patterns and in those in areas with obvious spatial patterns to be shrunk toward the global mean and local mean of the study area, respectively [21]. In this method, the posterior probability of θi does depend on the data Oi and Ei from the other regions (j≠i). In other words, the parameters of the prior distribution are not fixed, and will beare estimated empirically and based on all available data. Smoothing raw SIRs with empirical bayes Bayesian methods was done using second-order queen weights in GeoDa.
- Detection and identification of breast cancer clusters
- Neighborhood variation in the incidence of BC (regardless of staging), and in early and late stages at diagnosis were determined by the purely spatial scan statistic in a discrete Poisson model, using SaTScan version 9.4.2 (Harvard Medical School, Boston, MA, USA). The analysis requires the number of cases, population counts, and the geographical coordinates (longitude and latitude) for each location. The standard purely spatial scan statistic imposes a circular window (spatial cluster) on the map and it moves across the study area to compare the number of disease cases in a geographic area (θin) with disease cases outside that area (θout). Since the results of this analysis can be sensitive to model parameters, particularly window size, the maximum spatial cluster size is defined using the Gini coefficient [22]. It has been argued that the Gini coefficient is a very intuitive and systematic way to identify the best collection and non-overlapping of clusters [22].
- The number of cases in each location was Poisson-distributed, so we applied the exponential model-based spatial scan statistic using SaTScan. The likelihood ratio statistic (LRS) of the Poisson distribution (under the test hypothesis; Ho: θin=θout; Ha: θin ≠ θout) for a specific window is proportional to 1:
- where C is the total number of BC cases, c is the observed number of BC cases within a window, E[c] is the crude expected number of cases within the window under the null hypothesis, and C−E[c] is the expected number of cases outside the window.
- The statistical significance of the detected clusters was evaluated using randomization testing or Monte Carlo hypothesis testing because the exact distribution of the LRS was unknown. Under the null hypothesis, a large number of random datasets was generated and the LRS value for each random dataset was computed. ndom dataset was computed. The Monte Carlo p-value of a window was computed as
MATERIALS AND METHODS
Raw standardized incidence ratio
- There were 4,175 incident BC cases in the study area from 2008 to 2011, and of them, 3,080 were successfully geocoded to the neighborhood. The number of BC cases ranged from 0 to 86 across neighborhoods in Tehran. The highest incidence of female BC was found in northern Tehran (Figure 1). Based on the Moran index, the null hypothesis of zero spatial autocorrelation was rejected for the number of BC (Moran index, 0.08; p<0.05).
- Spatial distribution of breast cancer
- The results of the three methods we used (raw SIR, the BYM model, and the SEB method) indicate neighborhood-level inequality in the incidence of female BC in Tehran. The neighborhoods with higher than expected incidence of BC were in districts 1, 2, 3, 5, 6 and 7, in northern and central Tehran. The neighborhoods with lower than expected rates were in districts 15, 16, 17, 18, 19, 20, 21, and 22, in southern and southwestern Tehran (Figure 2).
- Figure 2A displays the estimated raw SIR of female BC in Tehran from 2008 to 2011. The median (interquartile range [IQR]) of female BC based on the raw SIR was 0.52 (1.33). The estimated raw SIR ranged from 0 to 14.84. In 82 neighborhoods, the raw SIR was 0 because no BC cases occurred in these neighborhoods; moreover, 37% of the neighborhoods had SIR values greater than 1. The smoothed SIRs using the SEB method are illustrated in Figure 2B. The median (IQR) of female BC based on the SEB method was 0.50 (1.13). As expected, there was a degree of shrinkage in the estimated SIR, such that in 2 neighborhoods the value of SIR was 0 and the range of SIRs was narrowed. The median (IQR) of female BC based on the BYM model was 0.60 (1.14), with no neighborhoods having a SIR of 0 and 30% of the neighborhoods having a SIR greater than 1 (Figure 2C).
- Spatial clusters of breast cancer
- Table 1 presents the characteristics of the most likely clusters of BC. Figure 3 displays the geographic pattern of the most likely clusters of BC. There was a statistical dispersion in the detected clusters of female BC incidence (Gini index, 0.47). The clusters with a higher than expected incidence of BC were found in the northern, northeastern, and central parts of the study area. Lower than expected incidence clusters of BC were found in the southern part of the study area. The most likely cluster of higher than expected BC incidence was located in areas near the center of Tehran, including neighborhoods in districts 3 and 6 with an observed-to-expected ratio of 3.92 (p<0.001), implying that the incidence of BC was 3.92 times greater within this cluster than in the rest of the study area. The most likely cluster of lower than expected BC incidence included the neighborhoods in districts 17, 18, and 19 with an observed-to-expected ratio of 0.05 (p<0.001), implying that the incidence of BC was 20 times lower within this cluster than in the rest of the study area.
RESULTS
- Neighborhood-level inequality in female BC incidence was found in Tehran from 2008 to 2011. The most likely clusters of higher than expected BC were found in central, northern, and northeastern Tehran, whereas the most likely clusters of lower than expected incidence were located in southern Tehran.
- Spatial analysis at finer scales can provide useful information about at-risk areas. Our results showed that the smoothed rates of BC incidence were variably distributed within specific districts; therefore, performing a spatial study at the district level would fail to identify these within-district inequalities. For example, on average, the neighborhoods in district 19 had lower rates of BC, but there were a few neighborhoods in this district with high rates of BC. Correspondingly, in general, the neighborhoods in districts 1, 2, and 3 had higher rates of BC, but there were a few neighborhoods with low rates within these districts.
- While the spatial analysis of cancer measures at geographic resolutions such as the census tract and zip code has been frequently conducted in developed countries [11,12,23,24], it has not received sufficient attention in developing countries. In Iran, the spatial analysis of cancer measures using GIS and SaTScan have mainly been conducted at the level of provinces or counties [13,25,26], such that evidence about the spatial patterns of cancer measures at finer resolutions such as the neighborhood level are limited. In one study by Rohani et al. [27], it was found that the population living in districts 1, 2, 3, and 6 had the highest age-specific rates of BC incidence.
- Smoothing the rates and conducting a spatial analysis with the SaTScan spatial scan statistic showed that the incidence of BC is a health problem in areas near the center and northern parts of Tehran, which correspond to wealthy areas with higher degrees of educational attainment and greater expenditures on health care activities [28]. It has been found that females living in wealthy areas had greater expenditures on health care activities such as screenings, resulting in BC being diagnosed more frequently [29]. Moreover, they have better access to cancer treatment facilities and adjuvant therapies, and likely have better survival rates [30].
- Several methodological issues involving spatial analysis with SaTScan should be mentioned. It has been argued that the hierarchical approach (SaTScan default) for selecting the maximum size of clusters may lead to unnecessarily large and less informative clusters [22]. In the current study, the maximum size of the spatial clusters was based on the Gini coefficient. It has been suggested that the Gini coefficient provides more information about non-overlapping clusters, while avoiding overly large clusters with relatively small relative risks and smaller clusters with higher relative risks [22]. SaTScan allows a better understanding of spatial patterns with adjustment for covariates. Previously published studies have demonstrated that adjustments for area-based characteristics, such as census tract poverty, and individual characteristics of patients, including age, race/ethnicity, or stage at diagnosis, can change the observed pattern of clusters [12,24].
- Our analysis has some advantages and limitations. The main advantage of the present study is that to our knowledge, this is the first study to explore the spatial patterns of female BC at the time of diagnosis at the neighborhood level in Iran. This type of spatial analysis at the neighborhood level can provide useful information to policy makers for the allocation of resources to truly needy areas. As expected, the raw SIRs per neighborhoods were dispersed due to extra-Poisson variability; to offset this challenge, we smoothed the raw SIRs using a BYM spatial model and the SEB method. The main objective of the BYM model is to take into account spatial autocorrelation in an efficient way, but the ability of the BYM model is limited where geographical units have different sizes and shapes [31]. One of the limitations of this study is related to how missing data may have induced bias in our results. Surveillance data, such as the data contained in cancer registries, are inevitably incomplete, and this is influenced by many factors such as sex, age, and socioeconomic status. As expected in ecological studies and spatial analysis, the ecological fallacy and the modifiable areal unit problem are potential sources of misleading interpretations. Another problem that was not accounted for in this study is the phenomenon known as the edge effect. This effect means that results for neighborhoods near administrative borders must be interpreted with caution, because, for example, the socioeconomic indicators of neighborhoods outside of the studied region may affect the characteristics of residents near the borders. Finally, the geocoding of the street addresses may have induced a degree of misclassification in the results.
- In conclusion, female BC incidence was differently distributed across neighborhoods in Tehran. Higher than expected spatial clusters of BC incidence appeared in central and northern parts of Tehran, whereas areas with lower than expected incidence were located in southern Tehran. These observations of neighborhood inequality can be a basis for the allocation of resources and the implementation of preventive strategies in truly needy areas.
DISCUSSION
ACKNOWLEDGEMENTS
Figure 1.The number of observed female breast cancer cases across neighborhoods in Tehran, 2008-2011.

Figure 2.The estimated standardized incidence ratio (SIR) of female breast cancer incidence in Tehran, 2008-2011. (A) Raw SIRs, (B) using the spatial empirical Bayesian method, and (C) using the Besag, York and Mollie (BYM) spatial model.
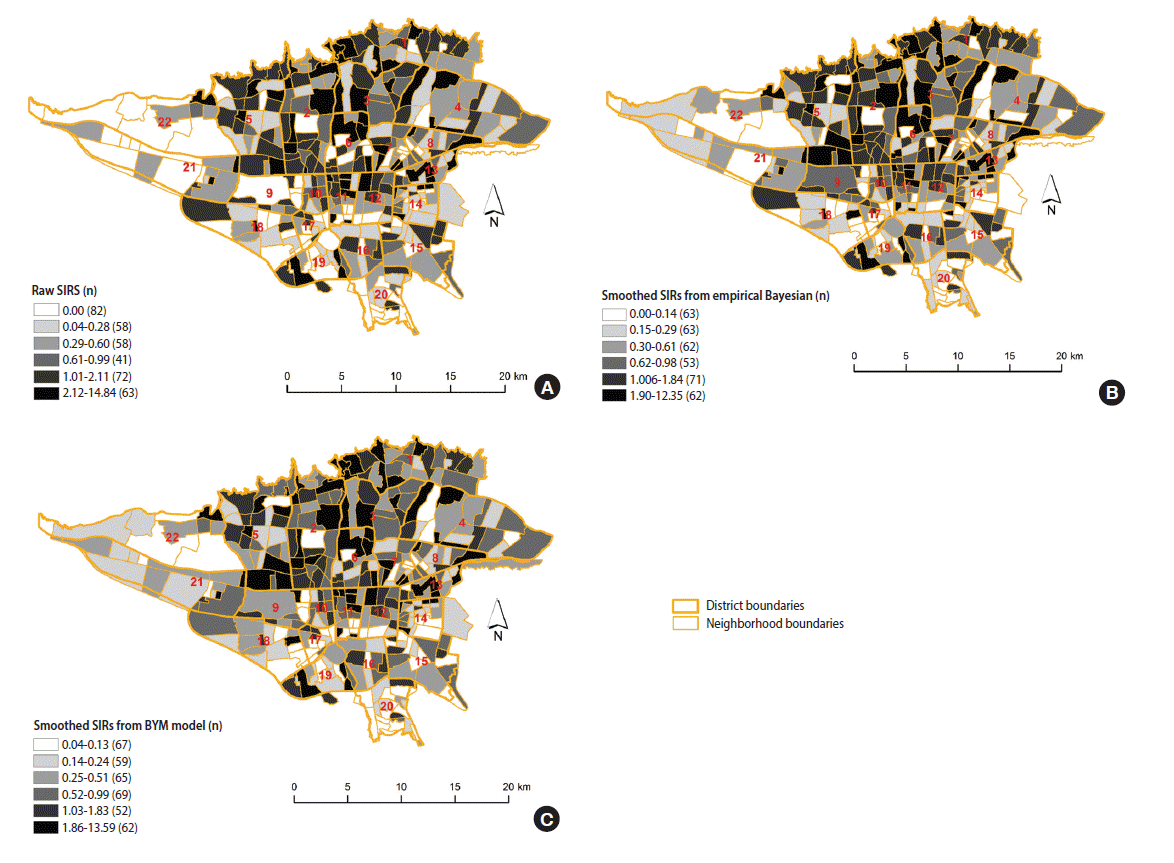
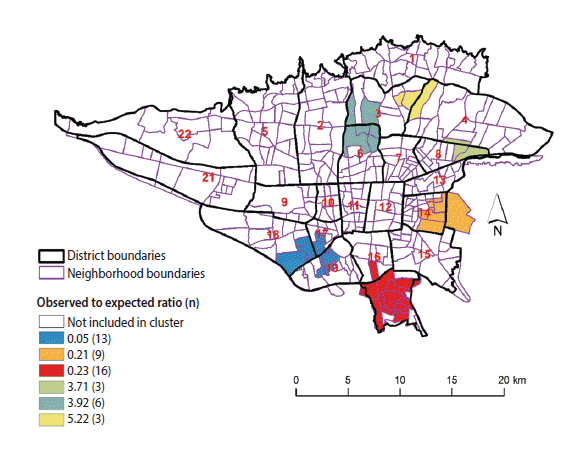
Table 1.High- and low-risk clusters for female BC incidence using spatial scan statistics in Tehran (2008-2011)
| Optimal Gini coefficient | MSC | Clusters detected | Involved districts | At-risk population | Observed cases (O) | Expected cases (E) | Annual cases per 100,000 | O/E | RR1 | p-value | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| Total BC incidence | (n=3,080) | ||||||||||
| Areas with high rates | 0.47 | 0.04 | Primary | 3, 6 | 58,039 | 217 | 55.37 | 126.4 | 3.92 | 4.14 | <0.001 |
| Secondary | 3, 4 | 29,134 | 145 | 27.79 | 165.9 | 5.22 | 5.43 | <0.001 | |||
| Tertiary | 4, 8 | 45,449 | 161 | 43.36 | 118.1 | 3.71 | 3.86 | <0.001 | |||
| Areas with low | Primary | 17, 18, 19 | 111,902 | 6 | 106.75 | 1.8 | 0.05 | 0.05 | <0.001 | ||
| rates | Secondary | 16, 20 | 124,216 | 27 | 118.50 | 7.2 | 0.23 | 0.22 | <0.001 | ||
| Tertiary | 14 | 113,341 | 23 | 108.12 | 6.8 | 0.21 | 0.21 | <0.001 |
- 1. Mousavi SM, Gouya MM, Ramazani R, Davanlou M, Hajsadeghi N, Seddighi Z. Cancer incidence and mortality in Iran. Ann Oncol 2009;20:556-563.ArticlePubMedPDF
- 2. Asadzadeh Vostakolaei F, Broeders MJ, Mousavi SM, Kiemeney LA, Verbeek AL. The effect of demographic and lifestyle changes on the burden of breast cancer in Iranian women: a projection to 2030. Breast 2013;22:277-281.ArticlePubMed
- 3. Harirchi I, Kolahdoozan S, Karbakhsh M, Chegini N, Mohseni SM, Montazeri A, et al. Twenty years of breast cancer in Iran: downstaging without a formal screening program. Ann Oncol 2011;22:93-97.ArticlePubMedPDF
- 4. Abdelsattar ZM, Hendren S, Wong SL. The impact of health insurance on cancer care in disadvantaged communities. Cancer 2017;123:1219-1227.ArticlePubMedPMC
- 5. Calo WA, Vernon SW, Lairson DR, Linder SH. Area-level socioeconomic inequalities in the use of mammography screening: a multilevel analysis of the Health of Houston Survey. Womens Health Issues 2016;26:201-207.ArticlePubMedPMC
- 6. Jedy-Agba E, McCormack V, Adebamowo C, Dos-Santos-Silva I. Stage at diagnosis of breast cancer in sub-Saharan Africa: a systematic review and meta-analysis. Lancet Glob Health 2016;4:e923-e935.ArticlePubMedPMC
- 7. Johns LE, Coleman DA, Swerdlow AJ, Moss SM. Effect of population breast screening on breast cancer mortality up to 2005 in England and Wales: an individual-level cohort study. Br J Cancer 2017;116:246-252.ArticlePubMedPMCPDF
- 8. Teng AM, Atkinson J, Disney G, Wilson N, Blakely T. Changing socioeconomic inequalities in cancer incidence and mortality: cohort study with 54 million person-years follow-up 1981-2011. Int J Cancer 2017;140:1306-1316.ArticlePubMed
- 9. Wang F, Luo L, McLafferty S. Healthcare access, socioeconomic factors and late-stage cancer diagnosis: an exploratory spatial analysis and public policy implication. Int J Public Pol 2010;5:237-258.ArticlePubMedPMC
- 10. Donohoe J, Marshall V, Tan X, Camacho FT, Anderson R, Balkrishnan R. Predicting Late-stage breast cancer diagnosis and receipt of adjuvant therapy: applying current spatial access to care methods in Appalachia. Med Care 2015;53:980-988.ArticlePubMedPMC
- 11. Dai D. Black residential segregation, disparities in spatial access to health care facilities, and late-stage breast cancer diagnosis in metropolitan Detroit. Health Place 2010;16:1038-1052.ArticlePubMed
- 12. Wan N, Zhan FB, Lu Y, Tiefenbacher JP. Access to healthcare and disparities in colorectal cancer survival in Texas. Health Place 2012;18:321-329.ArticlePubMed
- 13. Jafari-Koshki T, Schmid VJ, Mahaki B. Trends of breast cancer incidence in Iran during 2004-2008: a Bayesian space-time model. Asian Pac J Cancer Prev 2014;15:1557-1561.ArticlePubMedPDF
- 14. Mahaki B, Mehrabi Y, Kavousi A, Akbari ME, Waldhoer T, Schmid VJ, et al. Multivariate disease mapping of seven prevalent cancers in Iran using a shared component model. Asian Pac J Cancer Prev 2011;12:2353-2358.PubMed
- 15. Sadjadi A, Nouraie M, Ghorbani A, Alimohammadian M, Malekzadeh R. Epidemiology of breast cancer in the Islamic Republic of Iran: first results from a population-based cancer registry. East Mediterr Health J 2009;15:1426-1431.PubMed
- 16. Mohagheghi MA, Mosavi-Jarrahi A, Malekzadeh R, Parkin M. Cancer incidence in Tehran metropolis: the first report from the Tehran Population-based Cancer Registry, 1998-2001. Arch Iran Med 2009;12:15-23.PubMed
- 17. Lawson AB, Browne WJ, Rodeiro CL. Disease mapping with WinBUGS and MLwiN; 2003 [cited 2017 May 30]. Available from: https://leseprobe.buch.de/images-adb/d2/66/d266f974-a187-40b7-bf85-7c4b55c8f525.pdf.Article
- 18. Bilancia M, Fedespina A. Geographical clustering of lung cancer in the province of Lecce, Italy: 1992-2001. Int J Health Geogr 2009;8:40.ArticlePubMedPMC
- 19. Pedigo A, Aldrich T, Odoi A. Neighborhood disparities in stroke and myocardial infarction mortality: a GIS and spatial scan statistics approach. BMC Public Health 2011;11:644.ArticlePubMedPMCPDF
- 20. Kelsall J. Discussion of ‘Bayesian models for spatially correlated disease and exposure data’, by Best et al. Bayesian Stat 1999;6:151.
- 21. Pfeiffer DU, Robinson TP, Stevenson M, Stevens KB, Rogers DJ, Clements AC. Spatial analysis in epidemiology. Oxford: Oxford University Press; 2008. p 67-80.
- 22. Han J, Zhu L, Kulldorff M, Hostovich S, Stinchcomb DG, Tatalovich Z, et al. Using Gini coefficient to determining optimal cluster reporting sizes for spatial scan statistics. Int J Health Geogr 2016;15:27.ArticlePubMedPMC
- 23. Bambhroliya AB, Burau KD, Sexton K. Spatial analysis of county-level breast cancer mortality in Texas. J Environ Public Health 2012;2012:959343.ArticlePubMedPMCPDF
- 24. Henry KA, Niu X, Boscoe FP. Geographic disparities in colorectal cancer survival. Int J Health Geogr 2009;8:48.ArticlePubMedPMC
- 25. Goli A, Oroei M, Jalalpour M, Faramarzi H, Askarian M. The spatial distribution of cancer incidence in fars province: a GIS-based analysis of cancer registry data. Int J Prev Med 2013;4:1122-1130.PubMedPMC
- 26. Kavousi A, Bashiri Y, Mehrabi Y, Etemad K, Teymourpour A. Identifying high-risk clusters of gastric cancer incidence in Iran, 2004 - 2009. Asian Pac J Cancer Prev 2014;15:10335-10337.ArticlePubMedPDF
- 27. Rasaf MR, Ramezani R, Mehrazma M, Rasaf MR, Asadi-Lari M. Inequalities in cancer distribution in tehran; a disaggregated estimation of 2007 incidencea by 22 districts. Int J Prev Med 2012;3:483-492.PubMedPMC
- 28. Montazeri A, Vahdaninia M, Harirchi I, Harirchi AM, Sajadian A, Khaleghi F, et al. Breast cancer in Iran: need for greater women awareness of warning signs and effective screening methods. Asia Pac Fam Med 2008;7:6.ArticlePubMedPMC
- 29. Williams BA, Lindquist K, Sudore RL, Covinsky KE, Walter LC. Screening mammography in older women. Effect of wealth and prognosis. Arch Intern Med 2008;168:514-520.ArticlePubMed
- 30. Robinson M, Shipton D, Walsh D, Whyte B, McCartney G. Regional alcohol consumption and alcohol-related mortality in Great Britain: novel insights using retail sales data. BMC Public Health 2015;15:1.ArticlePubMedPMCPDF
- 31. Richardson S, Thomson A, Best N, Elliott P. Interpreting posterior relative risk estimates in disease-mapping studies. Environ Health Perspect 2004;112:1016-1025.ArticlePubMedPMC
REFERENCES
Figure & Data
References
Citations
Citations to this article as recorded by 
- Evaluation and comparison of spatial cluster detection methods for improved decision making of disease surveillance: a case study of national dengue surveillance in Thailand
Chawarat Rotejanaprasert, Kawin Chinpong, Andrew B. Lawson, Peerut Chienwichai, Richard J. Maude
BMC Medical Research Methodology.2024;[Epub] CrossRef - Clusters of high-risk, low-risk, and temporal trends of breast and cervical cancer-related mortality in São Paulo, Brazil, during 2000–2016
P.M.M. Bermudi, A.C.G. Pellini, C.S.G. Diniz, A.G. Ribeiro, B.S. de Aguiar, M.A. Failla, F. Chiaravalloti Neto
Annals of Epidemiology.2023; 78: 61. CrossRef - Variabilidade espacial intraurbana da mortalidade por câncer de mama e do colo do útero no município de São Paulo: análise dos fatores associados
Breno Souza de Aguiar, Alessandra Cristina Guedes Pellini, Elizabeth Angélica Salinas Rebolledo, Adeylson Guimarães Ribeiro, Carmen Simone Grilo Diniz, Patricia Marques Moralejo Bermudi, Marcelo Antunes Failla, Oswaldo Santos Baquero, Francisco Chiaravall
Revista Brasileira de Epidemiologia.2023;[Epub] CrossRef - Intra-urban spatial variability of breast and cervical cancer mortality in the city of São Paulo: analysis of associated factors
Breno Souza de Aguiar, Alessandra Cristina Guedes Pellini, Elizabeth Angélica Salinas Rebolledo, Adeylson Guimarães Ribeiro, Carmen Simone Grilo Diniz, Patricia Marques Moralejo Bermudi, Marcelo Antunes Failla, Oswaldo Santos Baquero, Francisco Chiaravall
Revista Brasileira de Epidemiologia.2023;[Epub] CrossRef - Breast cancer incidence in Yogyakarta, Indonesia from 2008–2019: A cross-sectional study using trend analysis and geographical information system
Bryant Ng, Herindita Puspitaningtyas, Juan Adrian Wiranata, Susanna Hilda Hutajulu, Irianiwati Widodo, Nungki Anggorowati, Guardian Yoki Sanjaya, Lutfan Lazuardi, Patumrat Sripan, Abdulkader Murad
PLOS ONE.2023; 18(7): e0288073. CrossRef - Evaluation of the association between centrosome amplification in tumor tissue of breast cancer patients and changes in the expression of CETN1 and CNTROB genes
Payam Kheirmand Parizi, Leila Mousavi Seresht, Seyed-Alireza Esmaeili, Ali Davarpanah Jazi, Abdolazim Sarli, Farinaz Khosravian, Mansour Salehi
Gene Reports.2022; 26: 101481. CrossRef - The Effect of Religious–Spiritual Psychotherapy on Illness Perception and Inner Strength among Patients with Breast Cancer in Iran
Safoora Davari, Isaac Rahimian Boogar, Siavash Talepasand, Mohamad Reza Evazi
Journal of Religion and Health.2022; 61(6): 4302. CrossRef - Geographic disparities in Saskatchewan prostate cancer incidence and its association with physician density: analysis using Bayesian models
Mustafa Andkhoie, Michael Szafron
BMC Cancer.2021;[Epub] CrossRef - Campania and cancer mortality: An inseparable pair? The role of environmental quality and socio-economic deprivation
Massimiliano Agovino, Massimiliano Cerciello, Gaetano Musella
Social Science & Medicine.2021; 287: 114328. CrossRef - The application of spatial empirical Bayesian smoothing method in spatial analysis of bacillary dysentery: A case study in Yudu County, Jiangxi Province
Yuwei Wang, Wang Gao
IOP Conference Series: Earth and Environmental Science.2020; 568(1): 012009. CrossRef - A Multi-Decadal Spatial Analysis of Demographic Vulnerability to Urban Flood: A Case Study of Birmingham City, USA
Mohammad Khalid Hossain, Qingmin Meng
Sustainability.2020; 12(21): 9139. CrossRef - Cancer mortality rates and spillover effects among different areas: A case study in Campania (southern Italy)
Massimiliano Agovino, Maria Carmela Aprile, Antonio Garofalo, Angela Mariani
Social Science & Medicine.2018; 204: 67. CrossRef - Spatial modeling of cutaneous leishmaniasis in Iranian army units during 2014-2017 using a hierarchical Bayesian method and the spatial scan statistic
Erfan Ayubi, Mohammad Barati, Arasb Dabbagh Moghaddam, Ali Reza Khoshdel
Epidemiology and Health.2018; 40: e2018032. CrossRef
 PubReader
PubReader ePub Link
ePub Link Cite
Cite