Articles
- Page Path
- HOME > Epidemiol Health > Volume 37; 2015 > Article
-
Original Article
Modeling and forecasting of the under-five mortality rate in Kermanshah province in Iran: a time series analysis - Mehran Rostami1, Abdollah Jalilian2, Behrooz Hamzeh3, Zahra Laghaei1
-
Epidemiol Health 2015;37:e2015003.
DOI: https://doi.org/10.4178/epih/e2015003
Published online: January 22, 2015
1Deputy of Public Health, Kermanshah University of Medical Sciences, Kermanshah, Iran
2Department of Statistics, Faculty of Sciences, Razi University, Kermanshah, Iran
3Research Center for Health Sciences, Department of Health Education and Promotion, School of Public Health, Kermanshah University of Medical Sciences, Kermanshah, Iran
- Correspondence: Abdollah Jalilian Department of Statistics, Faculty of Sciences, Razi University, Baq-e Abrisham Ave., Kermanshah 6714415111, Iran Tel: +98-83-34274561, Fax: +98-83-34274561, E-mail: jalilian@razi.ac.ir
• Received: November 18, 2014 • Accepted: January 5, 2015
©2015, Korean Society of Epidemiology
This is an open-access article distributed under the terms of the Creative Commons Attribution License (http://creativecommons.org/licenses/by/3.0/), which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
Abstract
-
OBJECTIVES:
- The target of the Fourth Millennium Development Goal (MDG-4) is to reduce the rate of under-five mortality by two-thirds between 1990 and 2015. Despite substantial progress towards achieving the target of the MDG-4 in Iran at the national level, differences at the sub-national levels should be taken into consideration.
-
METHODS:
- The under-five mortality data available from the Deputy of Public Health, Kermanshah University of Medical Sciences, was used in order to perform a time series analysis of the monthly under-five mortality rate (U5MR) from 2005 to 2012 in Kermanshah province in the west of Iran. After primary analysis, a seasonal auto-regressive integrated moving average model was chosen as the best fitting model based on model selection criteria.
-
RESULTS:
- The model was assessed and proved to be adequate in describing variations in the data. However, the unexpected presence of a stochastic increasing trend and a seasonal component with a periodicity of six months in the fitted model are very likely to be consequences of poor quality of data collection and reporting systems.
-
CONCLUSIONS:
- The present work is the first attempt at time series modeling of the U5MR in Iran, and reveals that improvement of under-five mortality data collection in health facilities and their corresponding systems is a major challenge to fully achieving the MGD-4 in Iran. Studies similar to the present work can enhance the understanding of the invisible patterns in U5MR, monitor progress towards the MGD-4, and predict the impact of future variations on the U5MR.
- The under-five mortality rate (U5MR) is a key pointer of child well-being including health status, and is also a broad indicator of social and economic progress [1,2]. It is one of the main indicators for assessing and monitoring progress in child health status with respect to the United Nations’ Millennium Development Goal 4 [1-4]. The target of the Fourth Millennium Development Goal (MDG-4) is to reduce the U5MR by two-thirds between 1990 and 2015 [2,5]. The U5MR is defined as the probability (per 1,000 live births) that a child will die before reaching the age of five if subject to current age-specific mortality rates [2]. Despite global population growth in recent decades, substantial progress has been made towards achieving MDG-4 in most countries of the world [1,2,6], as well as in Iran [6-9]. The number of under-five deaths worldwide has declined from nearly 12.7 million in 1990 to 6.3 million in 2013 [2]. Consequently, the global U5MR has dropped from almost 90 deaths per 1,000 live births in 1990 to 46 in 2013 [2]. However, this progress is not equally distributed at national and sub-national levels [2,4,10].
- Iran is a country that has experienced considerable reductions in the U5MR over the past decades [11]. In Iran, the U5MR was estimated as 281 per 1,000 live births in 1970 to 1975 [6] and declined from 46 per 1,000 live births in 1993 to 25 in 2005 [2]. Despite these gains, it has been seen that the decline in the U5MR across the country is heterogeneous and unequally distributed among provinces [2,12,13]. For example, in 2004, the estimate of the U5MR using data from the death registration system of the Ministry of Health and Medical Education was 28 per 1,000 live births for the whole country, while it was 32 per 1,000 live births in Kermanshah province in the west of Iran [11]. Thus, assessing fluctuations in the U5MR at the national level might not be sufficient and sub-national studies can provide a more detailed understanding of heterogeneity in the U5MR across the country. Moreover, since the U5MR is not constant over time, it is also important to understand how the rate evolves over time and explain its stochastic variations using a valid statistical model.
- The main purpose of this study was to detect any statistically significant features in the monthly U5MR in Kermanshah province from 2005 to 2012 and find an appropriate time series model that could adequately explain variations in the monthly U5MR. The study period of 2005 to 2012 was chosen because the child mortality data were available to the authors only for these years at the time of conducting the study.
INTRODUCTION
- Socio-demographic characteristics
- Kermanshah province is an undeveloped province located in the west of Iran and comprising 14 counties. Based on the population and housing census data of 2011, the population of Kermanshah province was 1,945,227 residents (about 2.6% of the Iranian population, 78 persons/km2 and 69.7% urbanization rate) with mainly Kurdish ethnic background [14].
- Ethics statement
- This study is based on the digital file of under-five mortality records available from the Deputy of Public Health, Kermanshah University of Medical Sciences. The data were anonymized and deidentified before usage and hence no informed consent was required for this work.
- Data source
- The monthly frequencies of under-five mortality in Kermanshah province were extracted from the digital file of the province mortality records from 2005 to 2012 (based on Iranian calendar time) in the provincial health jurisdiction. In this mortality digital file, under-five death records were collected from hospitals, health centers and health houses located in the province. There are few studies on sub-national child mortality in Iran, but a published report by the Iranian Ministry of Health showed that in 2010, more than 91% of mortality in the neonatal period and more than 63% of mortality 1 to 59 months after birth occurred in Iranian hospitals [15]. The frequencies were converted to rates per 1,000 live births using the number of under-five mortalities in each month as the numerator and births in the same month in the province as the denominator. Real times of live births were extracted from the National Organization for Civil Registration. A sequence of 96 monthly U5MRs was obtained and studied for temporal variations. Through the following steps, a time series analysis has been conducted on the data in order to identify structural patterns in the monthly U5MR in Kermanshah province from 2005 to 2012 and a short-term (six months) prediction has been made. See Appendix 1 and references therein for the technical details of the time series analysis.
- Data preparation
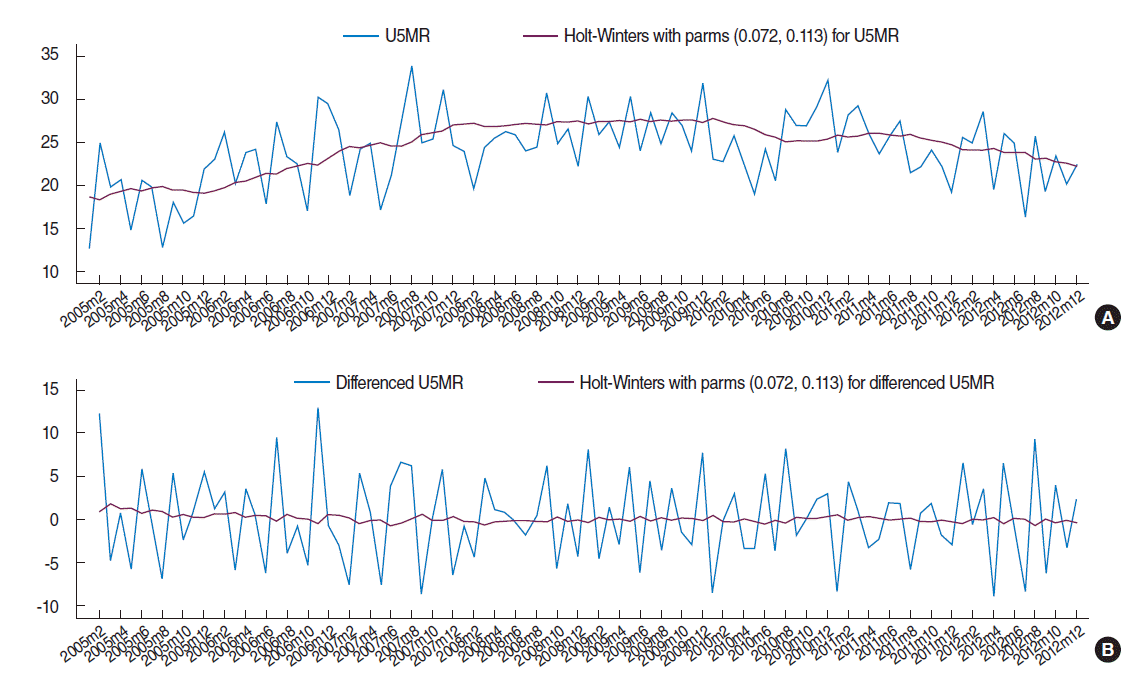
- Box-Cox transformation for assessment of stability in the data variance (p=0.20 for the null hypothesis of θ=1) shows that variance of the U5MR series is constant over time and no variance-stabilizing transformation is required. The Holt–Winters smoothing was applied to the U5MR series to examine any trends in the data. The time series plot of the original and the smoothed U5MR data are shown in Figure 1A. No seasonal or periodic components are clearly apparent in this plot but the smoothed series suggests an increasing trend, especially in the early years of the study period. Prais-Winsten regression also confirms (t=2.20, p=0.030) the presence of a significant linear trend with a positive slope. The augmented Dickey-Fuller unit root test accepts (lags=3, Z(t)=-2.51 and approximate p=0.112) the null hypothesis that the U5MR series has a unit root and indicates that the increasing trend in the data is stochastic and is caused by the effect of random shocks. Therefore, successive differencing could be performed on the U5MR to eliminate the unit root and hence the stochastic increasing trend and obtain a zero mean stationary time series. The first difference of the U5MR and its smoothed series are shown in Figure 1B. No trend is recognizable in the smoothed differenced series and the augmented Dickey-Fuller unit root test for the differenced series rejects (lags=3, Z(t) =-6.801 and approximate p<0.001) the null hypothesis of unit root and confirms that the first difference of the U5MR is a stationary time series.
- Model identification and estimation
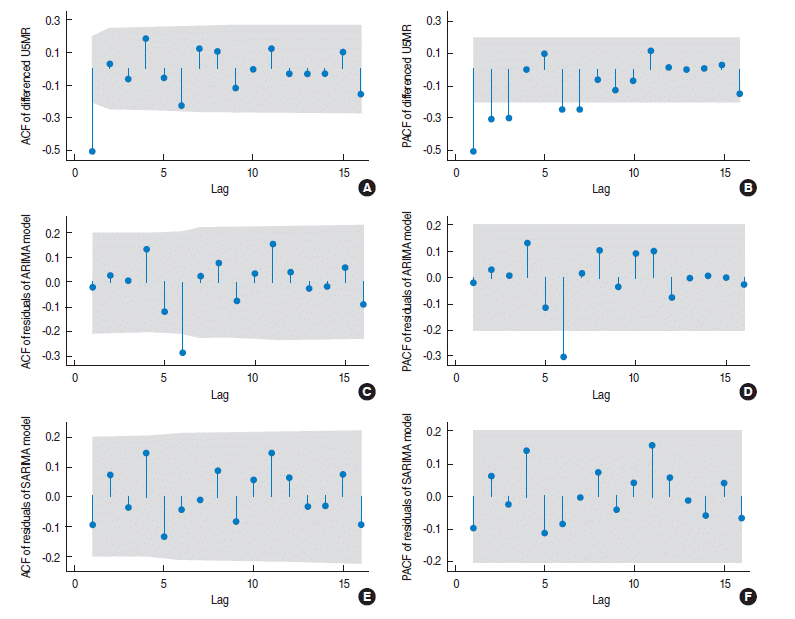
- The portmanteau Q-test (Q=91.89, p<0.001) and the Bartlett’s periodogram-based test (B=2.46, p<0.001) for white noise reject the null hypothesis of no serial correlation among observations of the differenced U5MR. To check the structure of such correlations, the sample autocorrelation function (ACF) and partial autocorrelation function (PACF) plots of the differenced U5MR series are shown in (A) and (B) of Figure 2. According to the plots, only the first lag of the ACF is significant (lying outside the grey 95% confidence bands) and the first few lags of PACF are decaying. The ACF and PACF of a first order moving average (MA), or auto-regressive integrated moving average (ARIMA) (0, 0, 1) time series have the same pattern and hence an ARIMA (0, 1, 1) model is appropriate for the original U5MR series. After fitting the ARIMA (0, 1, 1) model (Akaike information criterion [AIC]=534.2, Bayesian information criterion [BIC]=541.9) to the U5MR series and obtaining the model residuals, the ACF and PACF of the model residuals are plotted in Figure 2C and 2D. Both the ACF and PACF are significant at lag 6 (local spike) indicating that there is a six-monthly serial correlation in the data that the fitted ARIMA (0, 1, 1) model is not able to explain. This could be caused by a periodic (seasonal) component with period s=6. Thus, several seasonal auto-regressive integrated moving average (SARIMA) (p, d, q) (P, D, Q)6 models with different combinations of SARIMA (p, d, q) and (P, D, Q) orders were fitted to the U5MR series. Based on the corresponding AIC and BIC values of the fitted models, the best-fitting model was SARIMA (0, 1, 1) (0, 0, 1)6 with the smallest value of AIC=526.2 and BIC=533.9.
- Diagnostic checking
- According to Figure 3, there is no major discrepancy between the observed and expected U5MR from the fitted model (Figure 3A) and the model residuals vary randomly around zero (Figure 3B). In order to examine the adequacy of the fitted model, the ACF and PACF of the model residuals are shown in Figure (E) and (F) of Figure 2. All lags of ACF and PACF are within the 95% confidence bands, indicating that there is no correlation structure in the model residuals and hence that the fitted SARIMA model is adequate. This is also confirmed by the portmanteau Q-test (Q=37.4, p=0.59) and Bartlett’s periodogram-based test (B=0.60, p=0.86) for white noise, which accept the null hypothesis of no serial correlation in the model residuals. Moreover, the Shapiro-Wilk test (W=0.984, p=0.29), and Skewness-Kurtosis test (χ2=3.64, p=0.16) accept the normality assumption of the model residuals. Finally, the ARCH-LM test for heteroscedasticity in variance of the model residuals accepts (χ2= 0.004, p=0.951) the null hypothesis of no auto-regressive conditional heteroskedasticity effect. Therefore the overall goodness-of-fit of the model was evaluated.
- All analyses were performed using STATA/SE version 12.0 (StataCorp, College Station, TX, USA) [16] and the significance level was chosen at p-value<0.05.
MATERIALS AND METHODS
- According to the best-fitting model, the U5MR at month t, xt, is determined by
- where zt is a white noise process with standard deviation
- The six months ahead (short-term) predictions of the U5MR and their corresponding 95% prediction intervals based on the fitted SARIMA model are reported in Table 2. In general, the prediction intervals are wider for time series with a stochastic trend [17] and here relatively wide ranges of prediction intervals indicate the high uncertainty associated with the predictions. Using the most recent and more accurate data, such predictions can be used for monitoring and forecasting progress towards MDG-4.
RESULTS
- In this paper, time series analysis of monthly U5MR data in Kermanshah province in the west of Iran was conducted. According to our findings, the U5MR in Kermanshah province during the study period had a stochastic increasing trend. After primary analysis and applying necessary data adjustments, a SARIMA (0, 1, 1) (0, 0, 1)6 was selected as the best fitting model and model assessment and goodness-of-fit tests showed that the model can adequately explain the fluctuations in U5MR. Finally, predictions six months ahead of December 2012 and their corresponding prediction intervals were obtained based on the fitted model.
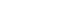
- Mortality data sources in developing countries, such as Iran [15,18,19], often suffer from various data availability and data quality issues [1,3,4] and among these issues the under-reporting of deaths and misreporting of ages are common [2,18]. For example, despite considerable efforts to decrease the U5MR in the whole country [2,6-9,11,15], the monthly U5MR in Kermanshah province shows a significant increasing trend during the study period. As demonstrated in Figure 4, the yearly U5MR in Kermanshah province was clearly lower than the estimated national average in 2005 and then higher than the estimated national average from 2007 to 2012. This discrepancy is most likely caused by under-reporting and misreporting of data in the earlier years and improving quality in data collection and registration coverage of U5MR data in the last years of the study period, which is remarkable for the health care system of Kermanshah province. Although there are some demographic methods for assessing causes and estimation of death under-numeration, these methods assume balanced population growth [15]. Iran has undergone drastic demographic changes during the recent three decades. Population growth had a high rate 30 years ago and afterwards dropped to low values [20,21]. These changes make use of demographic methods for estimation of death under-numeration difficult [15]; thus authors were obliged to use the available data for this study.
- Besides the possibility that the U5MR has been under-reported, another limitation of this study is that the available data cover a rather narrow time period of eight years due to restrictions in data availability. The third limitation of the study is that, although the model adequacy was evaluated by various statistical methods, the capability of the model for forecasting in short time periods and the accuracy of the predicted values by model are not assessed. The uncertainty of the predictions is assessed only by prediction intervals. However, it should be noticed that generating accurate estimates and predictions of child mortality is a considerable challenge for developing countries [1,2,4,10].
- Despite its limitations, the greatest strength of the present study is that it is the first study in Iran that uses time series analysis in order to mathematically model and predict an out-of-sample U5MR. However, additional data from other parts of the country are needed to generalize the results to the national level. In 2015, the MDG-4 target for the Iranian U5MR is 19 deaths per 1,000 live births [2]. It is currently around one year before the 2015 deadline of the goal and substantial progress has been made, but the progress remains insufficient to achieve MDG-4, particularly in Kermanshah province. It can be seen from Figure 4 that despite considerable progress in the past two decades towards reducing the U5MR in Iran [2,10,11], as well as in Kermanshah province [11,15], the burden of child deaths is higher than the nationally estimated and expected levels in this province.
- To achieve the MDG-4 on time, reducing under-five mortality inequities among Iranian provinces is an important priority. It seems that one of the major challenges ahead in fully achieving the MDG-4 in Iran is qualitative and quantitative improvement of under-five mortality data collection in health facilities and their corresponding systems. In general, for generating reliable mortality statistics at the sub-national levels it is necessary to improve the reporting and registering of child deaths by health facilities and to make sure that all child deaths that occur in health facilities are of critical importance. This is also crucial in understanding and measuring the impact and effectiveness of plans and interventions in this field. Since the definition of the U5MR indicator has not changed during the recent years, analyzing the invisible patterns and statistical modeling of this indicator within recent years is valuable and may enable health policy-makers to monitor the progress of Iranian child health status in order to evaluate the efficacy of health care systems. Such findings may be useful as they enhance the understanding of the current underlying patterns in the U5MR and monitoring of progress towards the MDG-4. Moreover, using studies similar to the present work, it is possible to predict the impact of future changes on this important child health indicator. Surely, with the expansion of study time periods and improvement of data collection methods, more accurate results will be obtained in the future.
DISCUSSION
ACKNOWLEDGEMENTS
Figure 1.Time series plot of (A) the original and smoothed under-five mortality rate (U5MR) data and (B) differenced U5MR.
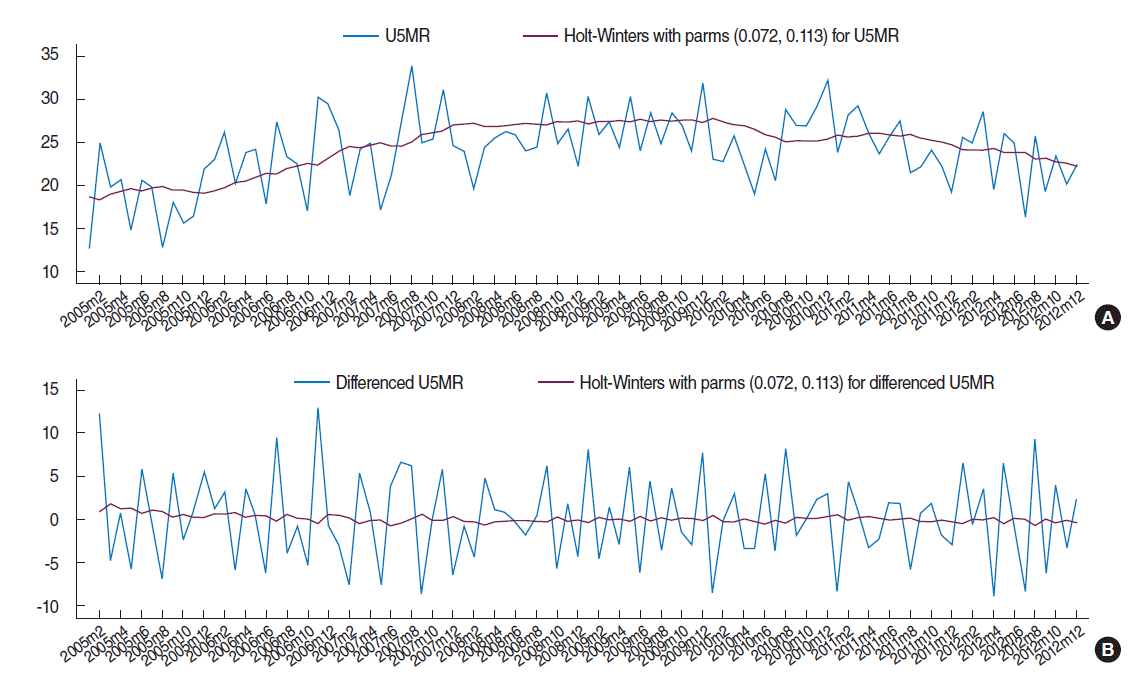
Figure 2.ACF (A, C, E) and PACF (B, D, F) plots of the differenced U5MR series (A, B), the residual of the fitted ARIMA (0, 1, 1) model (C, D), and the residuals of the fitted SARIMA (0,1,1) (0,0,1)6 model (E, F). U5MR, under-five mortality rate; ACF, autocorrelation function; PACF, partial autocorrelation function; ARIMA, auto-regressive integrated moving average; SARIMA, seasonal auto-regressive integrated moving average.
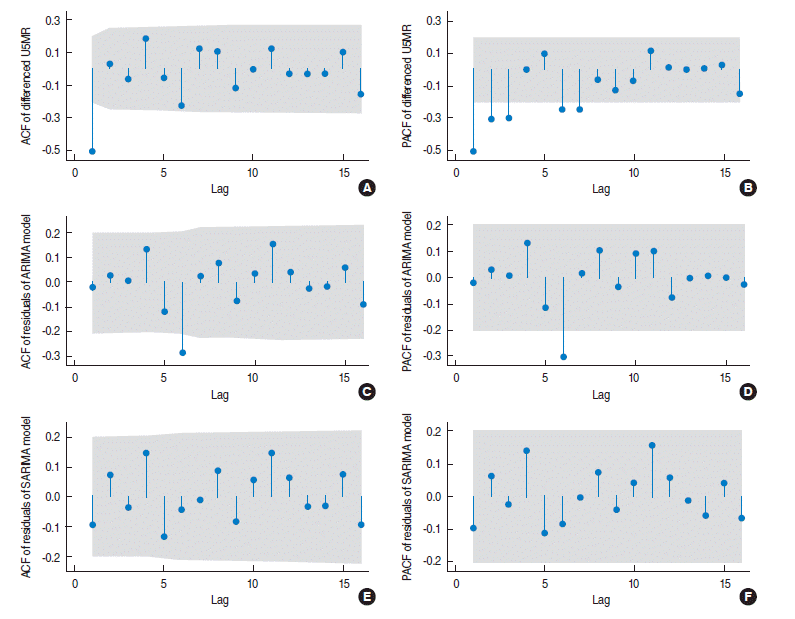
Figure 3.The observed and expected under-five mortality rate (U5MR) from the fitted model with their corresponding (A) 95% confidence limits and (B) model residuals.
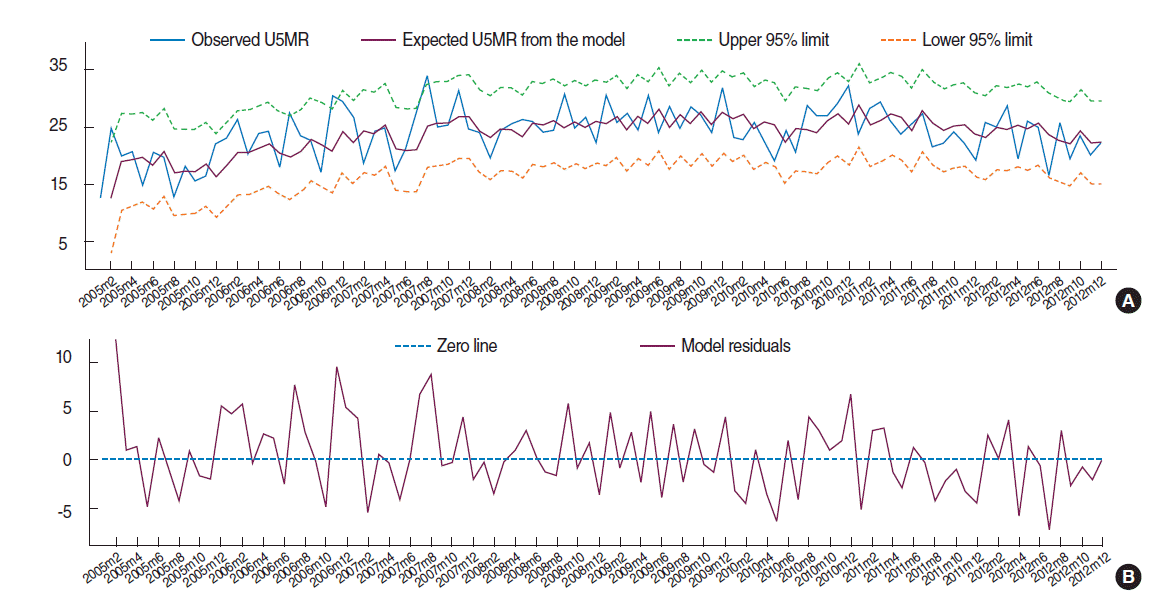
Figure 4.Yearly under-five mortality rate (deaths per 1,000 live births) in Kermanshah province from 2005 to 2012 (resulting from this study) and lower, middle and upper estimates of the yearly under-five mortality rate for Iran. Modified from UN Inter-agency Group for Child Mortality Estimation. Iran (Islamic Republic of): under-five mortality rate [22].

Table 1.Detailed description of estimated parameters of the fitted seasonal auto-regressive integrated moving average (0, 1, 1) (0, 0, 1)6 model to Kermanshah province monthly under-five mortality rate data
Table 2.The six-month-ahead predicted values of the under-five mortality rate with corresponding 95% lower and upper prediction intervals based on the fitted seasonal auto-regressive integrated moving average (0, 1, 1) (0, 0, 1)6 mode
- 1. Alkema L, New JR. Global estimation of child mortality using a Bayesian B-spline bias-reduction model; 2013 [cited 2014 Jul 20]. Available from: http://arxiv.org/abs/1309.1602.Article
- 2. UNICEF; World Health Organization; World Bank; United Nations. Levels & trends in child mortality report 2014: estimates developed by the UN Inter-Agency Group for Child Mortality Estimation. [cited 2015 Feb 17]. Available from: http://www.data.unicef.org/fckimages/uploads/1410869227_Child_Mortality_Report_2014.pdf.
- 3. Alkema L, New JR. Progress toward global reduction in under-five mortality: a bootstrap analysis of uncertainty in Millennium Development Goal 4 estimates. PLoS Med 2012;9:e1001355.ArticlePubMedPMC
- 4. Alkema L, New JR, Pedersen J, You D; UN Inter-agency Group for Child Mortality Estimation; Technical Advisory Group. Child mortality estimation 2013: an overview of updates in estimation methods by the United Nations Inter-agency Group for Child Mortality Estimation. PLoS One 2014;9:e101112.ArticlePubMedPMC
- 5. Silva R. Child mortality estimation: consistency of under-five mortality rate estimates using full birth histories and summary birth histories. PLoS Med 2012;9:e1001296.ArticlePubMedPMC
- 6. Amani F, Kazemnejad A. Changing pattern of mortality trends in iran, South, South-west Asia and world, 1970-2010. Iran J Public Health 2010;39:20-26.PubMedPMC
- 7. Heidari GR, Heidari RN. Iran Millennium Development Goals in a glance. Iran J Public Health 2009;38:63-64.
- 8. Moradi-Lakeh M, Bijari B, Namiranian N, Olyaeemanesh AR, Khosravi A. Geographical disparities in child mortality in the rural areas of Iran: 16-years trend. J Epidemiol Community Health 2013;67:346-349.ArticlePubMed
- 9. Movahedi M, Haghdoost AA, Pournik O, Hajarizadeh B, Fallah MS. Temporal variations of health indicators in Iran comparing with other Eastern Mediterranean Region countries in the last two decades. J Public Health (Oxf) 2008;30:499-504.ArticlePubMed
- 10. UNICEF; World Health Organization; World Bank; United Nations. Levels & trends in child report 2013: estimates developed by the UN Inter-agency Group for Child Mortality Estimation. [cited 2015 Feb 17]. Available from: http://www.unicef.org/media/files/2013_IGME_child_mortality_Report.pdf.
- 11. Khosravi A, Najafi F, Rahbar MR, Atefi A, Motlagh M, Kabir M. Health profile indicators in the Islamic Republic of Iran. Tehran: Ministry of Health and Medical Education, Deputy for Health; 2009. (Persian).
- 12. Amiri M, Lornejad HR, Barakati SH, Motlagh ME, Kelishadi R, Poursafa P. Mortality inequality in 1-59 months children across Iranian provinces: referring system and determinants of death based on hospital records. Int J Prev Med 2013;4:265-270.PubMedPMC
- 13. Motlagh ME, Kelishadi R, Barakati SH, Lornejad HR, Amiri M, Poursafa P. Distribution of mortality among 1-59 month-old children across Iranian provinces in 2009: the national mortality surveillance system. Arch Iran Med 2013;16:29-33.ArticlePubMed
- 14. Statistical Center of Iran. Implementation of the 2011 Iranian population and housing census in autumn (24 October–13 November 2011). [cited 2014 May 10]. Available from: http://www.amar.org.ir/Default.aspx?tabid=765. (Persian).
- 15. Khosravi A, Aghamohamadi S, Kazemi E, Pourmalek F, Shariati M. Mortality profile in Iran (29 provinces) over the years 2006 to 2010. Tehran: Ministry of Health and Medical Education, Deputy for Health; 2013. (Persian).
- 16. Becketti S. Introduction to time series using Stata. College Station: Stata Press; 2013. p 1-443.
- 17. Wei WS. Time series analysis: univariate and multivariate methods. Redwood City: Addison-Wesley Pub; 1994. p 1-614.
- 18. Khosravi A, Taylor R, Naghavi M, Lopez AD. Mortality in the Islamic Republic of Iran, 1964-2004. Bull World Health Organ 2007;85:607-614.ArticlePubMedPMC
- 19. Mohammadi Y, Parsaeian M, Farzadfar F, Kasaeian A, Mehdipour P, Sheidaei A, et al. Levels and trends of child and adult mortality rates in the Islamic Republic of Iran, 1990-2013; protocol of the NASBOD study. Arch Iran Med 2014;17:176-181.ArticlePubMed
- 20. Mehryar AH, Ahmad-Nia S, Kazemipour S. Reproductive health in Iran: pragmatic achievements, unmet needs, and ethical challenges in a theocratic system. Stud Fam Plann 2007;38:352-361.ArticlePubMed
- 21. Simbar M. Achievements of the Iranian family planning programmes 1956-2006. East Mediterr Health J 2012;18:279-286.ArticlePubMed
- 22. UN Inter-agency Group for Child Mortality Estimation. UN Inter-agency Group for Child Mortality Estimation. Iran (Islamic Republic of): under-five mortality rate. [cited 2015 Mar 15]. Available from: http://www.childmortality.org/index.php?r=site/graph#ID=IRN_ Iran.
- 23. Brockwell PJ, Davis RA. Introduction to time series and forecasting. New York: Springer; 2002. p 1-429.
- 24. Montgomery DC, Jennings CL. Kulahci M. Introduction to time series analysis and forecasting. Hoboken: Wiley-Interscience; 2008. p 1-472.
- 25. Chatfield C. The analysis of time series: an introduction. 6th. Boca Raton: Chapman & Hall; 2013. p 1-322.
- 26. Pridemore WA, Chamlin MB. A time-series analysis of the impact of heavy drinking on homicide and suicide mortality in Russia, 1956-2002. Addiction 2006;101:1719-1729.ArticlePubMedPMC
- 27. Zhang X, Liu Y, Yang M, Zhang T, Young AA, Li X. Comparative study of four time series methods in forecasting typhoid fever incidence in China. PLoS One 2013;8:e63116.ArticlePubMedPMC
- 28. Constenla D. Evaluating the costs of pneumococcal disease in selected Latin American countries. Rev Panam Salud Publica 2007;22:268-278.ArticlePubMed
REFERENCES
Appendix
Appendix 1.
Time series data
Data preparation
Model identification and estimation
Diagnostic checking
Prediction and prediction intervals
Figure & Data
References
Citations
Citations to this article as recorded by 
- Predicting the detection of leprosy in a hyperendemic area of Brazil: Using time series analysis
Vera Gregório, Dinilson Pedroza, Celivane Barbosa, Gilberto Bezerra, Ulisses Montarroyos, Cristine Bonfim, Zulma Medeiros
Indian Journal of Dermatology, Venereology and Leprology.2021; 87: 651. CrossRef - Forecasting Malaysia Under-5 Mortality Using State Space Model
N F Abd Nasir, A N Muzaffar, S N E Rahmat, W Z Wan Husin, N S Zainal Abidin
Journal of Physics: Conference Series.2020; 1496: 012001. CrossRef - Multivariate Long Memory Cohort Mortality Models
Hongxuan Yan, Gareth Peters, Jennifer Chan
SSRN Electronic Journal .2018;[Epub] CrossRef - Forecast analysis of any opportunistic infection among HIV positive individuals on antiretroviral therapy in Uganda
John Rubaihayo, Nazarius M. Tumwesigye, Joseph Konde-Lule, Fredrick Makumbi
BMC Public Health.2016;[Epub] CrossRef
 PubReader
PubReader ePub Link
ePub Link Cite
Cite