Articles
- Page Path
- HOME > Epidemiol Health > Volume 42; 2020 > Article
-
Brief Communication
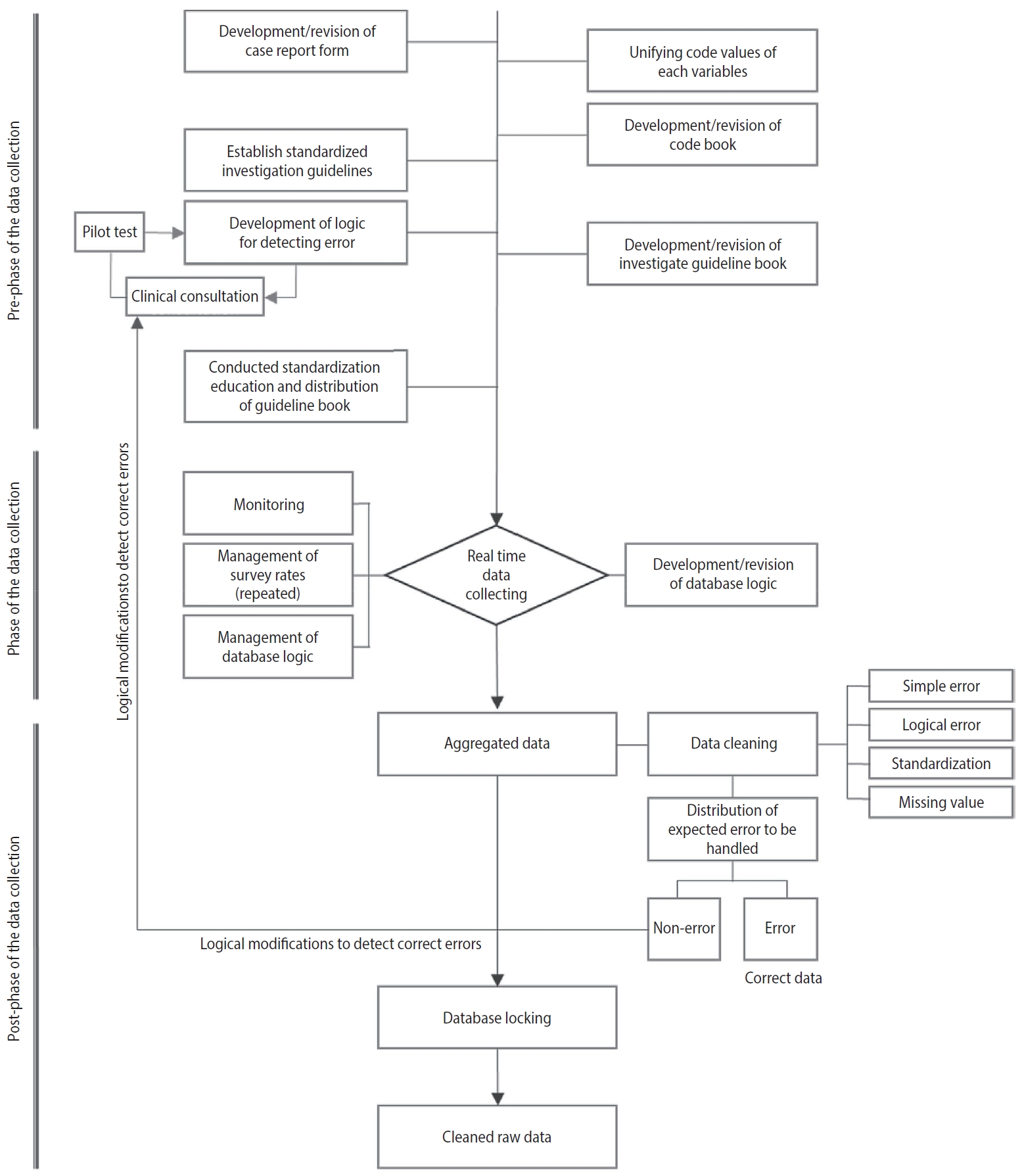
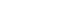
Prospective cohort data quality assurance and quality control strategy and method: Korea HIV/AIDS Cohort Study -
Soo Min Kim1,2,3*
 , Yunsu Choi3,4*, Bo Youl Choi3,4, Minjeong Kim3, Sang Il Kim5, Jun Young Choi6, Shin-Woo Kim7, Joon Young Song8, Youn Jeong Kim9, Mee-Kyung Kee10, Myeongsu Yoo10, Jeong Gyu Lee10, Bo Young Park4
, Yunsu Choi3,4*, Bo Youl Choi3,4, Minjeong Kim3, Sang Il Kim5, Jun Young Choi6, Shin-Woo Kim7, Joon Young Song8, Youn Jeong Kim9, Mee-Kyung Kee10, Myeongsu Yoo10, Jeong Gyu Lee10, Bo Young Park4 -
Epidemiol Health 2020;42:e2020063.
DOI: https://doi.org/10.4178/epih.e2020063
Published online: September 4, 2020
1Department of Applied statistics, Yonsei University College of Commerce and Economics, Seoul, Korea
2Department of Statistics and Data Science, Yonsei University College of Commerce and Economics, Seoul, Korea
3Institute for Health and Society, Hanyang University, Seoul, Korea
4Department of Preventive Medicine, Hanyang University College of Medicine, Seoul, Korea
5Division of Infectious Disease, Department of Internal Medicine, Seoul St. Mary’s Hospital, College of Medicine, The Catholic University of Korea, Seoul, Korea
6Department of Internal Medicine and AIDS Research Institute, Yonsei University College of Medicine, Seoul, Korea
7Department of Internal Medicine, Kyungpook National University School of Medicine, Daegu, Korea
8Division of Infectious Diseases, Department of Internal Medicine, Korea University College of Medicine, Seoul, Korea
9Division of Infectious Disease, Department of Internal Medicine, Incheon St. Mary’s Hospital, College of Medicine, The Catholic University of Korea, Incheon, Korea
10Division of Viral Disease Research Center for Infectious Disease Research, Korea National Institute of Health, Cheongju, Korea
- Correspondence: Bo Youl Choi Department of Preventive Medicine, Hanyang University College of Medicine, 222 Wangsimni-ro, Seongdong-gu, Seoul 04763, Korea E-mail: bychoi@hanyang.ac.kr
- *Kim & Choi contributed equally to this work as joint first authors.
©2020, Korean Society of Epidemiology
This is an open-access article distributed under the terms of the Creative Commons Attribution License (http://creativecommons.org/licenses/by/4.0/), which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
Figure & Data
References
Citations
- Adopting Data to Care to Identify and Address Gaps in Services for Children and Adolescents Living With HIV in Mozambique
Belmiro Sousa, Sergio Chiale, Hayley Bryant, Lisa Dulli, Tanya Medrano
Global Health: Science and Practice.2024;[Epub] CrossRef - Effect of characteristics on the clinical course at the initiation of treatment for human immunodeficiency virus infection using dimensionality reduction
Yunsu Choi, Bo Youl Choi, Sang Il Kim, Jungsoon Choi, Jieun Kim, Bo Young Park, Soo Min Kim, Shin-Woo Kim, Jun Yong Choi, Joon Young Song, Youn Jeong Kim, Hyo Youl Kim, Jin-Soo Lee, Jung Ho Kim, Yoon Hee Jun, Myungsun Lee, Jaehyun Seong
Scientific Reports.2023;[Epub] CrossRef - A Nationwide Evaluation of the Prevalence of Human Papillomavirus in Brazil (POP-Brazil Study): Protocol for Data Quality Assurance and Control
Jaqueline Driemeyer Correia Horvath, Marina Bessel, Natália Luiza Kops, Flávia Moreno Alves Souza, Gerson Mendes Pereira, Eliana Marcia Wendland
JMIR Research Protocols.2022; 11(1): e31365. CrossRef
 PubReader
PubReader ePub Link
ePub Link Cite
Cite